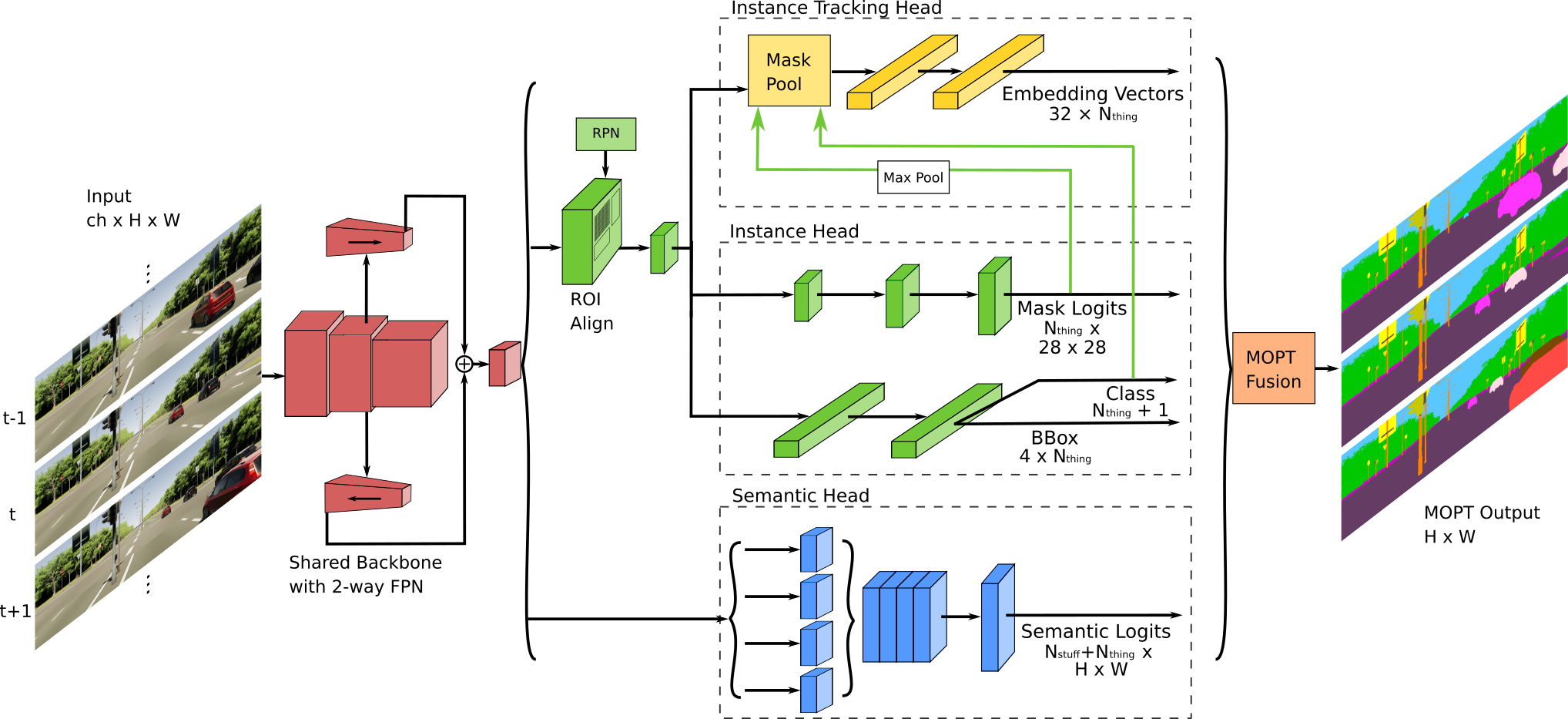
MOPT unifies the distinct tasks of semantic segmentation (pixel-wise classification of ‘stuff’ and ‘thing’ classes), instance segmentation (detection and segmentation of instance-specific ‘thing’ classes) and multi-object tracking (detection and association of ‘thing’ classes over time). The goal of this task is to encourage holistic modeling of dynamic scenes by tackling problems that are typically addressed disjointly in a coherent manner.
MOPT Demo
Deep Convolutional Neural Networks for Multi-Object Panoptic Tracking
This demo contains PanopticTrackNet trained on Virtual KITTI 2 and SemanticKITTI datasets. Select a dataset to load from the drop down box below and click on an image in the carosel to see the results. To learn more about the network architecture and the approach employed, please see the Technical Approach section below.
Please Select a Model:
Selected Dataset:
Virtual KITTI 2